The Age of Research: Why Scaling Alone Won't Solve AI's Generalization Gap
_We are leaving the era of easy scaling and returning to the hard work of architectural invention. The next frontier isn't just bigger models—it's models that c...

We are leaving the era of easy scaling and returning to the hard work of architectural invention. The next frontier isn't just bigger models—it's models that can truly learn.
Summary
For the past five years, the dominant strategy in artificial intelligence has been deceptively simple: scale. By pouring more data and compute into transformer architectures, the industry achieved the spectacular leaps seen in GPT-3 and GPT-4. But a quiet consensus is emerging that this 'Age of Scaling'—where progress was a predictable function of capital investment—is ending. We are re-entering an 'Age of Research,' characterized by uncertainty, architectural experimentation, and the need for fundamental breakthroughs rather than just larger clusters.
This essay explores the technical and philosophical hurdles defining this new era. It examines the 'generalization gap' between biological and artificial intelligence, arguing that true reasoning requires more than rote memorization of the internet. It details the critical role of 'value functions' in reinforcement learning—the ability to evaluate a thought process before it concludes—and why this mechanism is the key to moving from chatbots to reasoning agents. Finally, it considers the immense stakes of the next phase: the construction of continent-sized compute clusters and the imperative to align superintelligence with the interests of sentient life.
Key Takeaways; TLDR;
- The 'Age of Scaling' (2020–2025) provided predictable gains, but the industry is returning to an 'Age of Research' where progress requires novel invention.
- Current models suffer from a 'generalization gap': they require orders of magnitude more data than humans to learn simple concepts.
- The '10,000-hour student' analogy explains why models can pass hard exams but fail at basic adaptation—they rely on memorized patterns rather than fluid intelligence.
- Value functions are the missing link for reasoning; they allow an agent to realize it is on the wrong path before it finishes a task.
- Biological intelligence remains the benchmark for sample efficiency, likely due to a superior learning algorithm rather than just evolutionary priors.
- The future of AI development may involve 'continent-sized' compute clusters, necessitating rigorous alignment focused on sentient life. It is a strange paradox of the current moment that the arrival of artificial intelligence feels both inevitable and abstract. We see the headlines—companies investing billions, models passing the bar exam—but for the average person, the economic fabric of daily life remains largely unchanged. This 'slow takeoff' feels contradictory to the exponential graphs we are shown, but it points to a deeper reality: the low-hanging fruit of the last five years has been harvested.
From roughly 2012 to 2020, the field of deep learning was in an Age of Research. Progress was jagged, driven by tinkerers and scientists inventing new architectures (AlexNet, Transformers, ResNets) often on modest hardware. Then, around 2020, the industry stumbled upon a powerful simplification: Scaling Laws. The realization was that if you simply poured more data and compute into the existing recipe, performance improved predictably . This ushered in the Age of Scaling, a period where capital expenditure could substitute for scientific breakthrough. It was a time of certainty; if you built it bigger, they would come.
But that era is drawing to a close. The data is finite, and the models, while encyclopedic, are revealing fundamental brittleness. We are drifting back into an Age of Research—a time where simply making the model larger is no longer enough. The next leap requires solving the puzzle of generalization.
The Generalization Gap: Memorization vs. Talent
To understand why scaling is hitting a wall, we must distinguish between competence and comprehension. Current Large Language Models (LLMs) are often compared to a specific type of student. Imagine a student who decides to master competitive programming by practicing for 10,000 hours. They memorize every algorithm, every edge case, and every proof technique. When they sit for the exam, they score perfectly because they have seen every variation of the problem before.
Now imagine a second student. They have only practiced for 100 hours. They haven't memorized the library of solutions, but they possess a fluid, adaptable intelligence—the 'it' factor. In a standardized test, the first student might beat the second. But in the messy, undefined reality of a career, the second student will almost certainly outperform the first.
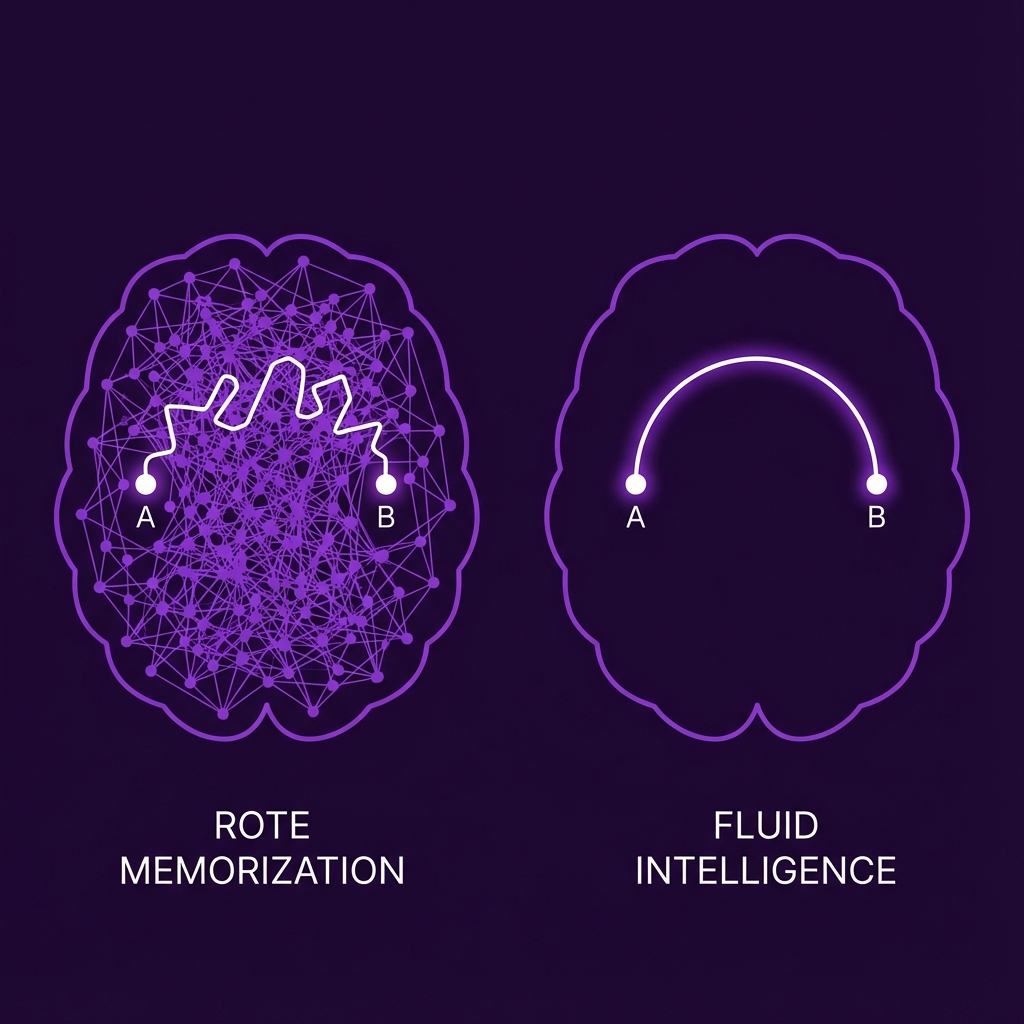
The difference between memorization (left) and generalization (right). Current models rely on the former; the goal of the new research era is the latter.
Current AI models are the first student. They have 'practiced' on the entire internet—trillions of tokens of text. Their performance on benchmarks is superhuman because, in a sense, they have already seen the test questions (or close variations of them) during training. This is why a model can write complex Python code but then fail to fix a simple bug without introducing a new one, cycling endlessly between two errors. It lacks the robust, underlying mental model of why the code works; it only knows what the code usually looks like.
This distinction is what researcher François Chollet calls 'skill-acquisition efficiency' . True intelligence isn't just skill at a specific task; it is the ability to acquire new skills with minimal data. By this metric, despite their vast knowledge, current models are remarkably unintelligent.
The Return of the Value Function
If pre-training (reading the internet) is the equivalent of the 10,000-hour student's cramming session, how do we build the second student? The answer likely lies in Reinforcement Learning (RL) and the development of robust value functions.
In classical machine learning, models are often trained to simply predict the next word. They don't 'think' about the future; they just react. Contrast this with how a grandmaster plays chess. They don't need to play a game to the bitter end to know they've made a mistake. If they lose their queen, a mental alarm bell rings immediately. They have an internal value function—a gut sense—that evaluates a board state and says, "This is bad, go back."
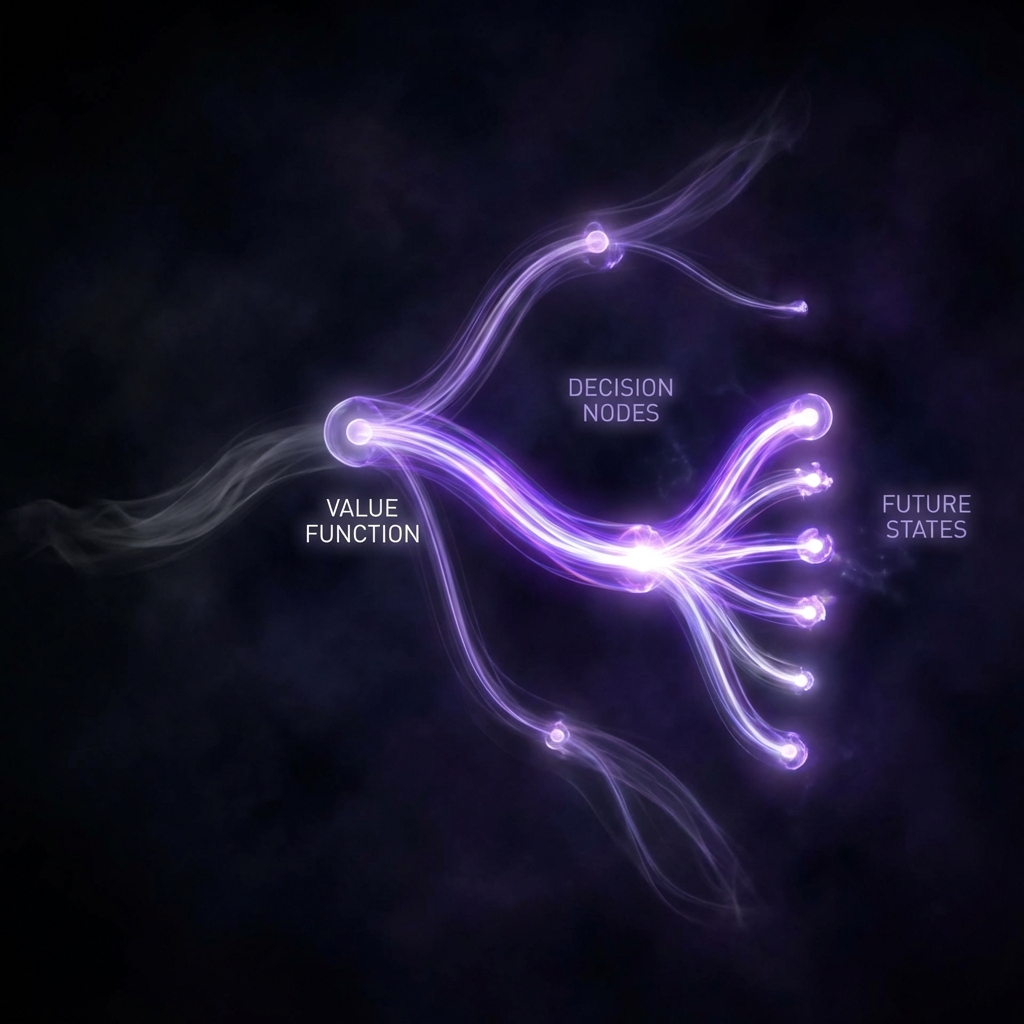
A value function allows an agent to prune unpromising 'thought branches' early, a critical capability for complex reasoning that current LLMs largely lack.
For complex reasoning tasks—like mathematics or software engineering—current models lack this internal critic. They generate a solution token by token, often realizing they have gone down a blind alley only after they have wasted paragraphs of text. They cannot 'short-circuit' a bad thought process.
The next frontier of research involves training models not just to mimic text, but to explore paths of reasoning and evaluate them against a value function before committing to an answer. This is the principle behind recent advancements like OpenAI's o1 and DeepSeek's R1 . By allowing the model to generate 'thought trajectories'—internal monologues where it tests hypotheses—we can simulate the trial-and-error process that characterizes human thinking.
However, this is harder than it sounds. In chess, the reward is clear (checkmate). In writing code or proving a theorem, the 'reward' is sparse. You might work for hours (or thousands of tokens) before you know if your approach is valid. Teaching a neural network to value intermediate steps—to know that this specific line of reasoning is promising while that one is a dead end—is the central challenge of the new Age of Research.
The Biological Benchmark: Why Humans Learn Faster
There is a haunting question that hangs over the field: Why are humans so efficient? A teenager can learn to drive a car in roughly 20 hours of practice. They don't crash thousands of times to learn what 'off-road' means. They don't need to drive a billion miles. They generalize from a tiny amount of data.
Some argue this is because of evolutionary priors—that millions of years of survival have hard-coded our brains with basic physics and spatial reasoning. We aren't starting from scratch; we are starting from a pre-trained checkpoint of 'mammalian survival.'
But this explanation is insufficient. Humans excel at tasks that evolution could never have anticipated, like coding in C++ or solving differential equations. We display high reliability in domains that didn't exist 50 years ago, let alone 50,000. This suggests that our advantage isn't just a library of instincts, but a fundamentally superior learning algorithm.
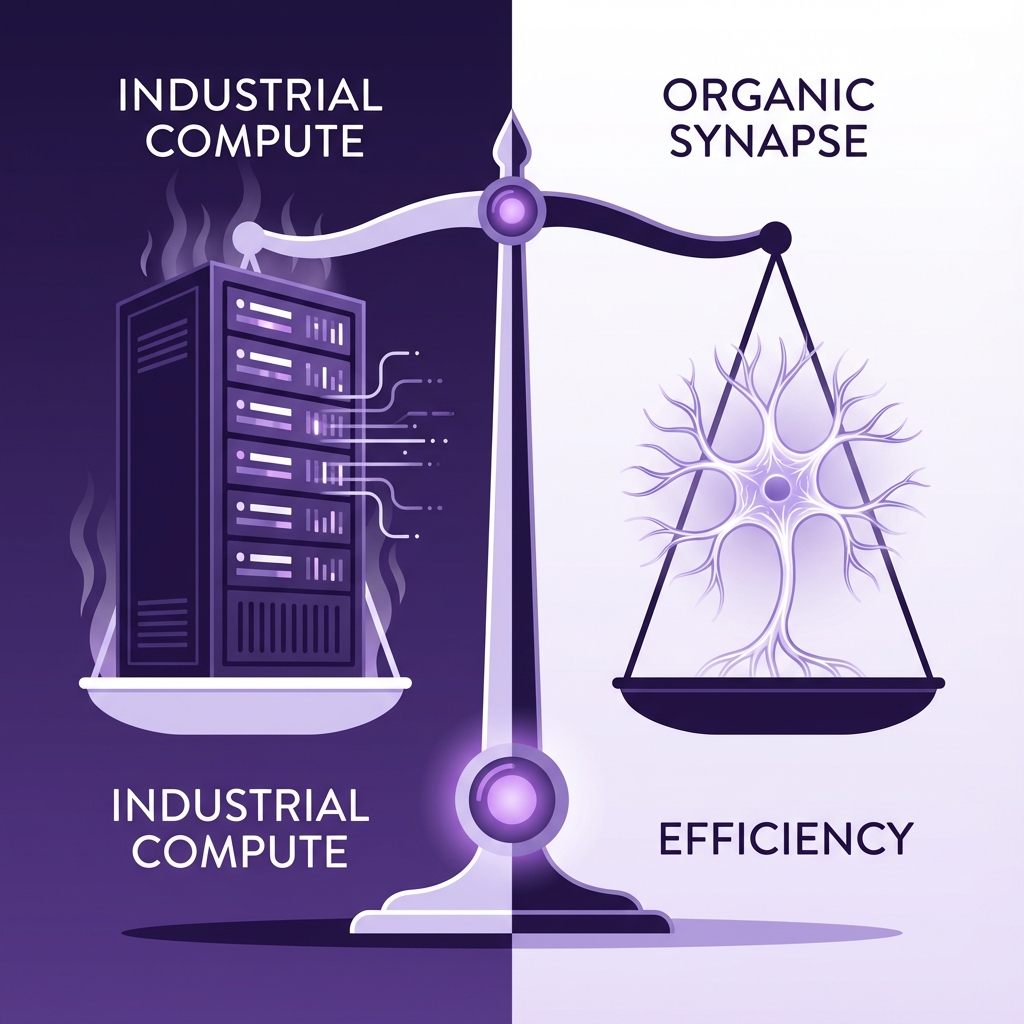
The efficiency gap: Biological intelligence achieves generalization with a fraction of the energy and data required by silicon-based systems.
Our brains are doing something that deep learning currently is not. We engage in unsupervised experimentation; we build causal models; we use emotions as crude but effective value functions to guide our learning. A child doesn't need a labeled dataset to learn gravity; they just drop a spoon and watch it fall. Until AI can replicate this 'unsupervised' learning from interaction—rather than just passive consumption of text—the generalization gap will remain.
The Alignment Imperative in the Age of Superclusters
As we move back into an era of research, the physical scale of the infrastructure is paradoxically growing larger. We are approaching the construction of 'continent-sized' compute clusters—data centers consuming gigawatts of power. If the research bets pay off, and we unlock the 'human-like learning algorithm' on this scale, the result will be a system of unprecedented power.
This brings us to the ultimate trade-off: Capabilities vs. Control.
If we create a system that learns as efficiently as a human but runs on silicon at million-times speed, we face an alignment crisis. The traditional approach has been 'gradual release'—deploying slightly smarter models every year so society (and the developers) can adapt. This allows us to patch bugs as they appear, much like aviation safety improved through the analysis of crashes.
However, there is a contrarian view: the 'straight shot.' The argument is that the market is a rat race that forces compromises on safety. A lab insulated from commercial pressure could theoretically take the time to solve the 'superalignment' problem before releasing anything. But this is a gamble. It assumes you can solve safety in a vacuum, without the real-world stress testing that comes from deployment.
The goal of this alignment must be specific. It is not enough to align AI with 'human values,' which are often contradictory and shifting. A more robust target might be an alignment with sentient life. If an AI is itself sentient—a controversial but possible emergent property of sufficiently complex value functions—it may be easier to align it based on a shared understanding of consciousness and suffering.
Conclusion: The Unmapped Path
We are standing at a threshold. The era of 'easy' progress—where we could simply scale up the parameters and watch the loss curve drop—is over. The path forward is steeper and requires the kind of fundamental ingenuity that defined the early days of the field.
We need to move from memorization to generalization, from prediction to reasoning, and from passive consumption to active learning. The labs that succeed in this new Age of Research will not just build bigger encyclopedias; they will build the first true digital thinkers. The economic and societal impact of such a creation will not be 'abstract' for long.
I take on a small number of AI insights projects (think product or market research) each quarter. If you are working on something meaningful, lets talk. Subscribe or comment if this added value.
Appendices
Glossary
- Value Function: In reinforcement learning, a function that estimates the expected future reward of a given state or action. It allows an agent to judge if it is in a 'good' position without needing to finish the entire task.
- Generalization Gap: The disparity between a model's performance on training data (or similar tasks) and its ability to adapt to novel, unseen scenarios. A high generalization gap implies the model has memorized rather than learned.
- Pre-training: The initial phase of training an AI model on a massive dataset (like the internet) to learn general patterns of language and world knowledge, before fine-tuning for specific tasks.
- RL (Reinforcement Learning): A machine learning paradigm where an agent learns to make decisions by performing actions and receiving rewards or penalties, rather than being explicitly told the correct answer.
Contrarian Views
- Scaling is not dead: Many researchers argue that we have not actually hit the limits of scaling, and that better data curation and hardware optimization will allow the 'Age of Scaling' to continue for another decade.
- Evolutionary Priors are dominant: Some evolutionary biologists and neuroscientists argue that the human 'learning algorithm' is actually quite simple, and our efficiency is almost entirely due to 3 billion years of pre-encoded instincts (priors), which AI cannot easily replicate without massive simulation.
Limitations
- Speculative Nature: The transition to an 'Age of Research' is a prediction, not a guaranteed historical fact. It is possible that a new scaling breakthrough renders this analysis obsolete.
- Opaque Industry: Much of the data regarding the 'plateauing' of models is held within private labs (OpenAI, Anthropic, Google) and is not publicly verifiable.
Further Reading
- On the Measure of Intelligence (Chollet) - https://arxiv.org/abs/1911.01547
- The Bitter Lesson (Rich Sutton) - http://www.incompleteideas.net/IncIdeas/BitterLesson.html
References
- Scaling Laws for Neural Language Models - arXiv (journal, 2020-01-23) https://arxiv.org/abs/2001.08361 -> Foundational paper establishing the 'Age of Scaling' by demonstrating the power law relationship between compute/data and performance.
- On the Measure of Intelligence - arXiv (journal, 2019-11-05) https://arxiv.org/abs/1911.01547 -> Defines intelligence as 'skill-acquisition efficiency' rather than task-specific skill, underpinning the argument about the generalization gap.
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning - DeepSeek AI (whitepaper, 2025-01-22) https://arxiv.org/abs/2501.12948 -> Provides a concrete example of the shift to RL and 'thinking' models (value functions) discussed in the essay.
- Ilya Sutskever: SSI, Scaling, and the Future of AI - Dwararkesh Patel (video, 2024-09-01) https://www.youtube.com/watch?v=1yvBqas -> The primary source material for the essay's core arguments regarding the 'Age of Research' and SSI's strategy.
- The AI Solow Paradox - National Bureau of Economic Research (journal, 2017-11-01) https://www.nber.org/papers/w24001 -> Contextualizes the 'slow takeoff' and the disconnect between AI capabilities and economic productivity.
- Energy Efficiency in Artificial and Biological Intelligence - Neurozone (org, 2024-10-15) https://www.neurozone.com/resources/energy-efficiency-in-artificial-and-biological-intelligence -> Provides data on the massive energy efficiency gap between the human brain (12-20W) and AI clusters.
- Learning to Reason with LLMs (OpenAI o1) - OpenAI (org, 2024-09-12) https://openai.com/index/learning-to-reason-with-llms/ -> Demonstrates the industry shift toward 'chain of thought' and RL-based reasoning to solve the generalization problem.
- Will AI Scaling Continue Through 2030? - Epoch AI (org, 2024-01-01) https://epochai.org/blog/will-ai-scaling-continue-through-2030 -> Discusses the limits of data exhaustion and the necessity of new approaches beyond simple scaling.
- Superintelligence: Paths, Dangers, Strategies - Oxford University Press (book, 2014-07-03) https://global.oup.com/academic/product/superintelligence-9780199678112 -> Foundational text on the risks of 'instrumental convergence' and the need for careful alignment.
- Brain-inspired computing: The extraordinary energy efficiency of the human brain - Human Brain Project (org, 2023-09-04) https://www.humanbrainproject.eu/en/brain-simulation/brain-inspired-computing/ -> Supports the biological benchmark argument regarding the efficiency of neural computation.
Recommended Resources
- Signal and Intent: A publication that decodes the timeless human intent behind today's technological signal.
- Blue Lens Research: AI-powered patient research platform for healthcare, ensuring compliance and deep, actionable insights.
- Outcomes Atlas: Your Atlas to Outcomes — mapping impact and gathering beneficiary feedback for nonprofits to scale without adding staff.
- Lean Signal: Customer insights at startup speed — validating product-market fit with rapid, AI-powered qualitative research.
- Qualz.ai: Transforming qualitative research with an AI co-pilot designed to streamline data collection and analysis.
Ready to transform your research practice?
See how Thesis Strategies can accelerate your next engagement.